Система QPSLab для
анализа и распознавания числовых последовательностей с квазипериодической
структурой
Описание демо-версии программы распознавания последовательности,
включающей серии идентичных фрагментов, для случая известного числа фрагментов
Демонстрационная версия программы работает с фиксированным алфавитом эталонов.
После запуска программы появляется окно
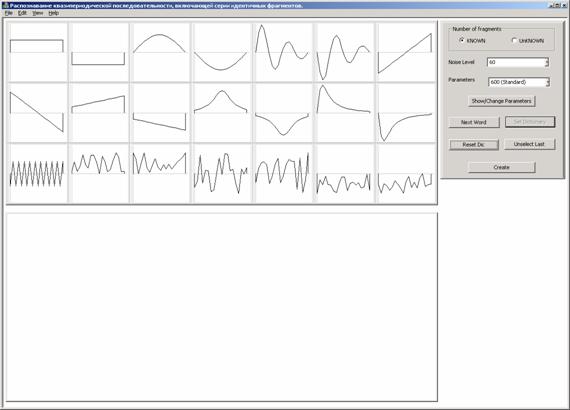
Изображения компонент информационных векторов – алфавита эталонов (21 эталон) –
расположены в левом верхнем углу. Поле, расположенное под алфавитом
предназначено для формирования словаря. Слева сверху расположена панель
управляющих клавиш.
Для
создания и последующей обработки последовательности следует задать словарь,
выбрать образец, в соответствии с которым будет генерироваться
квазипериодическая последовательность, указать параметры генерации, после чего
нажать кнопку
Create.
Создание словаря
осуществляется следующим образом. С помощью последовательности кликов по
элементам алфавита выбираются эталоны, которые следует добавить в образец. Для
завершения ввода очередного набора эталонов нажимается кнопка
NextWord.
После ее нажатия система ожидает ввода следующего набора эталонов. После ввода
последнего набора в желаемый словарь эту кнопку можно не нажимать. Если
какая-либо комбинация эталонов попала в словарь ошибочно, ее ввод можно отменить
нажатием клавиши
UnselectLast.
Кроме того, клавиша
ResetDic
полностью очищает окно формирования словаря (после ее нажатия содержимое словаря
опустошается), тот же эффект может быть достигнут многократным нажатием
UnselectLast.
Выбор образца.
По умолчанию, в качестве образца для генерации последовательности выбирается
первый из введенных, он расположен внизу окна формирования словаря. Выбранный
образец окрашен синим цветом. Для того чтобы выбрать в качестве образца другой
набор эталонных элементов, находящийся в окне формирования словаря, достаточно
щелкнуть по нему правой клавишей мыши (выбранный образец окрасится в синий
цвет).
Для
установки параметров генерации последовательности следует выполнить одну
или несколько из нижеперечисленных операций.
Parameters
установить параметры генерации последовательности. В программе предусмотрены
три типовых набора параметров с длинами последовательности 200, 600 и 1200
соответственно, кроме того, возможна генерация последовательности с
произвольным набором параметров (см. следующий пункт).
Посмотреть или изменить значения параметров генерации. Для этого
используется кнопка
Show/Chance
parameters.
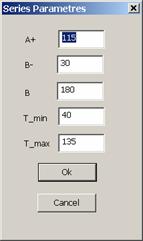
При
ее нажатии появляется окно ввода параметров
Здесь
А+
– правая граница возможного положения для первого фрагмента в
последовательности, а
В-
и В
– соответственно левая и правая граница для последнего фрагмента,
T_min
и
T_max
– соответственно нижняя и верхняя границы для интервала между фрагментами. Длина
последовательности определяется как
В+20,
здесь 20 – длина эталонов алфавита. При нажатии кнопки
Ok
производится проверка введенных параметров на допустимость. В случае
благоприятного исхода новые значения параметров принимаются, иначе выдается
сообщение об ошибке, после чего идет возврат к окну ввода параметров.
После
задания образца и параметров генерации окно программы выглядит, например,
следующим образом
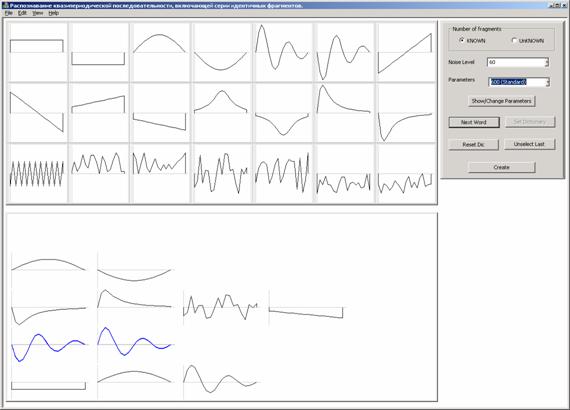
Здесь
задан словарь, включающий 4 набора эталонов, в качестве образца выбран второй
снизу набор эталонов (выделен синим цветом), установлен уровень шума 60 и
стандартный набор параметров для генерации последовательности длины 600.
При
нажатии кнопки
Create
производится генерация и обработка последовательности, в окне программы
появляются результаты обработки
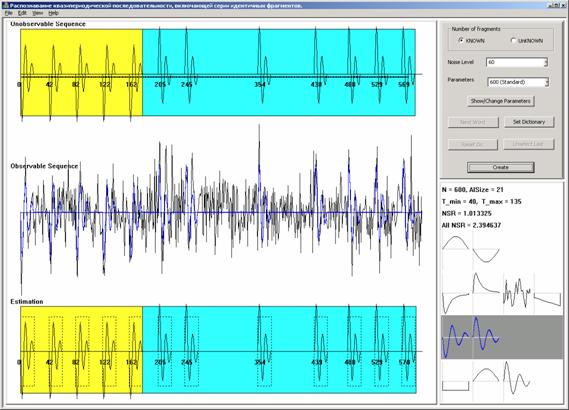
В левой
части окна расположены: недоступная для наблюдения исходная последовательность,
подлежащая обработке искаженная аддитивным гауссовским шумом наблюдаемая
последовательность и последовательность, восстановленная в результате работы
программы. Цветом выделено разбиение на серии. Под графиком исходной
последовательности нанесены значения начальных номеров информационных
фрагментов, под графиком восстановленной последовательности – их оценки.
Справа
снизу расположена основная информация о работе алгоритма, а именно:
-
основные параметры генерации (длина последовательности, размер алфавита,
минимальный и максимальный интервалы между фрагментами);
-
словарь, причем образец прорисован синим цветом, а фоновое поле результата
распознавания выделено серым цветом (в данном примере результат
распознавания совпадает с образцом);
-
NSR (Noise
to Signal Ratio)
– отношение помеха/сигнал, вычисленное по участкам,
соответствующим информационным фрагментам;
-
All NSR
(Noise
to Signal Ratio)
– отношение помеха/сигнал, вычисленное по всей
последовательности.
Для
продолжения работы можно
Create
для
генерации и обработки последовательности с тем же образцом и
параметрами генерации;
с
помощью щелчка левой кнопкой мыши сменить образец (словарь и параметры
генерации при этом остаются неизменными);
изменить параметры генерации как описано выше, словарь при этом не
изменится;
перейти к редактированию словаря с помощью кнопки
SetDictionary.
Данную
программу можно использовать так же для распознавания последовательностей в
условиях, когда априорная информация об общем числе фрагментов в
последовательности недоступна, для этого достаточно перевести переключатель
Number
of Fragments
в
положение
UnKNOWN.
По умолчанию этот переключатель установлен в положение
KNOWN,
что соответствует алгоритму распознавания последовательности, включающей
известное число фрагментов.